Prédire le résultat des élections présidentielles
présentation du projet
Pour une de nos MSPR (Mise en situation professionelle) nous avons été chargés de prédire les résultats des élections présidentielles. La première étape a consisté à collecter les données nécessaires pour entraîner notre modèle. Cette tâche a impliqué une recherche approfondie sur des sites comme Data.gouv et l’INSEE.
Une fois les données récupérées, nous les avons transformées pour les intégrer dans une base de données. Nous avons utilisé Talend, un outil ETL (Extraction, Transformation, Chargement), pour cette tâche. La mise en place de cette étape a été complexe et chronophage, mais ma contribution principale a été la réalisation des prédictions en Python.
Réalisation de la tâche
Nous avons commencé par extraire les données des différentes tables dans notre base de données :
# Example of code highlighting
input_string_var = input("Enter some data: ")
with engine.begin() as conn:
querypres = text("SELECT * FROM mspr2_presidentielles")
df_pres = pd.read_sql_query(querypres, conn)
querychom = text("SELECT * FROM mspr2_chomeurs")
df_chom = pd.read_sql_query(querychom, conn)
queryinfla = text("SELECT * FROM mspr2_inflation")
df_infla = pd.read_sql_query(queryinfla, conn)
querypop = text("SELECT * FROM mspr2_population")
df_pop = pd.read_sql_query(querypop, conn)
queryinfraction_departement = text("SELECT * FROM mspr2_infraction_departement")
df_infraction_departement = pd.read_sql_query(queryinfraction_departement, conn)
queryimpots = text("SELECT * FROM mspr2_impots")
df_impots = pd.read_csv(io.BytesIO(uploaded['impots_formatted_2022.csv']))
querySmic = text("Select * from mspr2_smic")
df_smic = pd.read_sql_query(querySmic, conn)
querydicparti = text("select * from mspr2_bord_parti")
df_parti = pd.read_sql_query(querydicparti, conn)
Nous avons ensuite fusionné les différents DataFrames pour en créer un seul contenant tous les indicateurs nécessaires :
df_indicateur = df_chom.merge(df_infla, on='annee', how='outer')
df_indicateur = df_indicateur.merge(df_pop, on=['annee', 'code_dep'], how='outer')
df_indicateur = df_indicateur.merge(df_infraction_departement, on=['annee', 'code_dep'], how='outer')
df_indicateur = df_indicateur.merge(df_impots, on=['annee', 'code_dep'], how='outer')
df_indicateur = df_indicateur.merge(df_smic, on=['annee'], how='outer')
Nous avons remplacé le nom du parti par le bord politique pour mieux cibler notre prédiction. Ensuite, nous avons utilisé la méthode groupby pour regrouper les données par année, code département, tour, et bord politique :
#remplacement du nom des parti par leurs bord
df_pres['parti'] = df_pres['parti'].map(df_parti.set_index('parti')['bord'])
df_pres = df_pres.rename(columns={'parti': 'bord'})
aggregation_functions = {
'voix': 'sum',
'inscrits': lambda x: x.iloc[0],
'votants': lambda x: x.iloc[0],
'exprime': lambda x: x.iloc[0],
'blanc_nul' : lambda x: x.iloc[0],
}
df_grouped = df_pres.groupby(['annee', 'code_dep', 'tour', 'bord']).agg(aggregation_functions).reset_index()
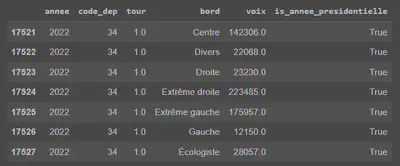
Voici un aperçu simplifié du DataFrame après traitement :
Nous avons également créé des boxplots pour mieux visualiser nos données et obtenir une vue plus claire des distributions :
Pour entraîner notre modèle, nous avons utilisé une Random Forest, qui s’est révélée être l’algorithme le plus performant pour notre cas. Voici un extrait du code d’entraînement :
data_train = data_train.drop(data_train[data_train.annee == 2022].index)
X_train = data_train.drop('voix', axis=1)
y_train = data_train['voix']
data_train_2022 = datas_Train.copy()
data_train_2022 = data_train_2022.drop(data_train_2022[data_train_2022.annee != 2022].index)
X_Test_2022 = data_train_2022.drop('voix', axis=1)
Y_Test_2022 = data_train_2022['voix']
rf = RandomForestRegressor(n_estimators=100, max_depth=18, random_state=115)
rf.fit(X_train, y_train)
y_pred_2022 = rf.predict(X_Test_2022)
X_train.head()
La Random Forest, étant un ensemble d’arbres de décision, a montré une précision de 80% dans nos prédictions. Nous avons également analysé l’impact des différents paramètres sur le nombre de voix
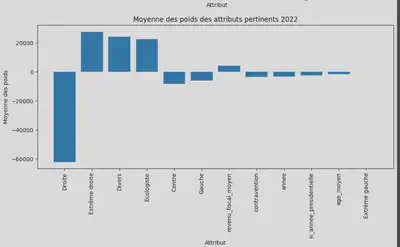
Il ressort que, pour ces prédictions, le bord politique de droite tend à perdre des voix, tandis que l’extrême droite tend à en gagner. Les paramètres ayant le plus d’impact, en dehors des bords politiques eux-mêmes, sont le revenu fiscal moyen et les contraventions.
Enfin, nous avons modélisé la différence entre les données réelles et les résultats prédits :
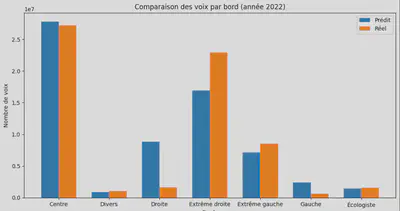
Les résultats de notre expérience sont plutôt concluants. Pour des raisons pédagogiques et de simplicité, nous avons réalisé nos prédictions sur une année où les élections étaient déjà passées. Une prochaine étape pourrait être de prédire les résultats d’une élection à venir en intégrant également des prévisions pour les autres indicateurs.